In recent years, as we navigate the age of artificial intelligence, a plethora of new terms have entered the lexicon. Some older concepts have gained renewed attention, one of which is the “Neural Network.” This term is becoming increasingly prevalent, and its relevance is likely to grow.
What is Deep Learning? How is it Different from Machine Learning?
Artificial intelligence systems, such as automatic translation and speech recognition, have surged in prominence over the last decade, largely due to a technique known as “deep learning.” This approach is essentially a modern iteration of the “neural network,” a concept that has been around for over 70 years. To demystify what a neural network is, let’s delve into its intricacies.
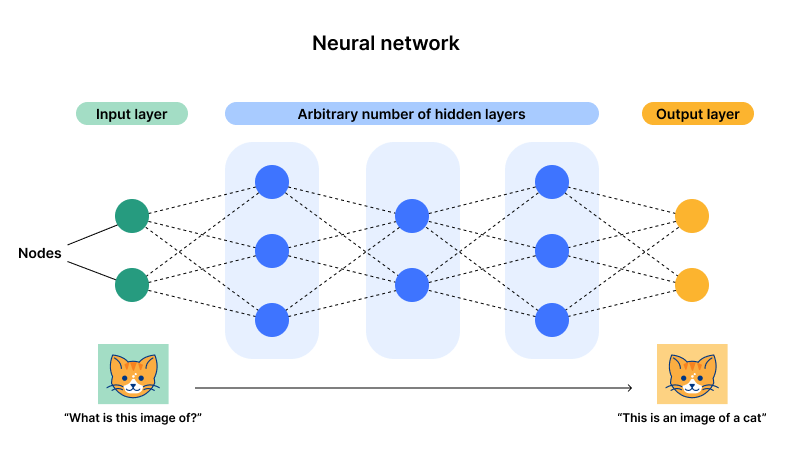
At its core, a neural network enables a computer to learn specific tasks by analyzing training data (machine learning). This mimics how the human brain processes data. Typically, examples are manually labeled in advance. For instance, an object recognition system may be trained with thousands of labeled images depicting objects like phones or soccer balls, allowing it to identify visual patterns associated with these labels.
Elaborating further, a neural network is a machine learning model that emulates human brain function, employing processes that mimic the interaction of biological neurons to discern facts, evaluate options, and draw conclusions. These networks, sometimes called artificial neural networks (ANNs) or simulated neural networks (SNNs), are a subset of machine learning and central to deep learning models.
Each neural network consists of layers of nodes, or artificial neurons, arranged in an input layer, one or more hidden layers, and an output layer. Each node is interconnected and has an associated weight and threshold. If a node’s output surpasses the threshold, it activates and transmits data to the next network layer. Otherwise, the data transmission halts.
Neural networks rely on training data to enhance their accuracy over time. Once fine-tuned, they become potent tools in computer science and artificial intelligence, facilitating rapid data classification and clustering. A notable example of neural network application is Google’s search algorithm.
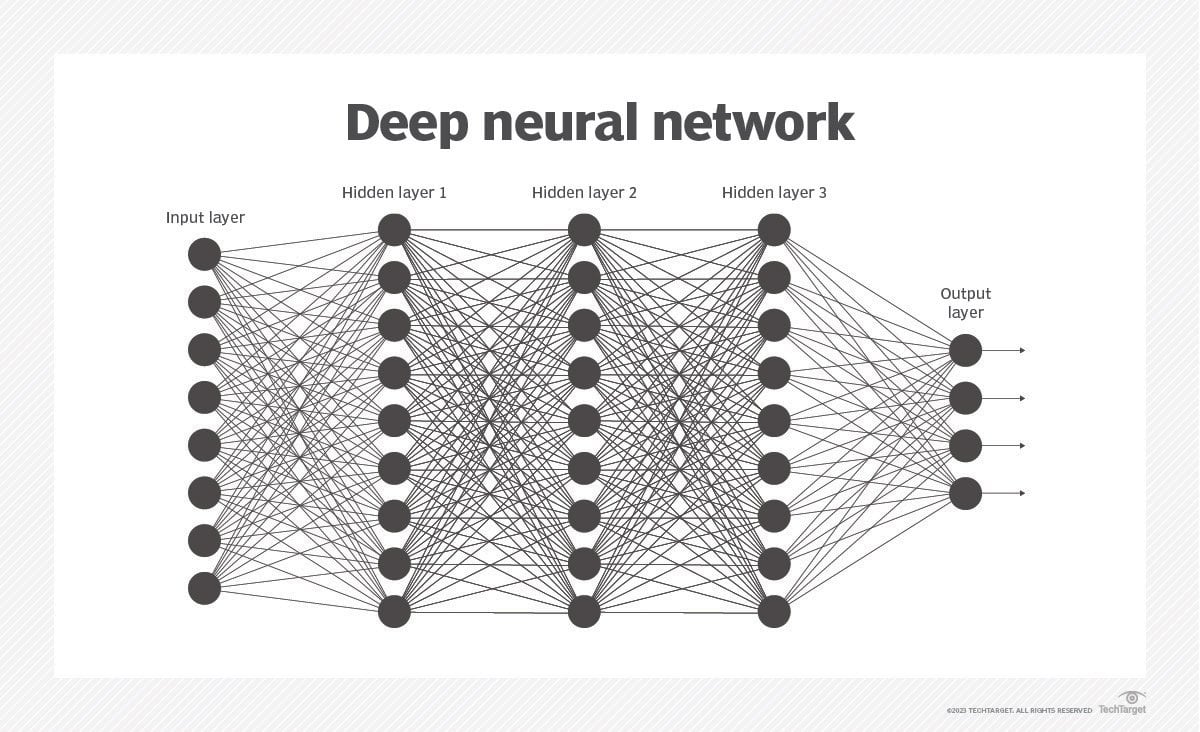
In simple terms, these networks consist of algorithms designed to recognize patterns and relationships in data, akin to human cognitive processes. Fundamentally, a neural network comprises neurons, the basic units resembling brain cells. These neurons receive inputs, process them, and yield an output. Neurons are organized into layers: an Input Layer receiving inputs, several Hidden Layers processing data, and an Output Layer delivering final predictions or decisions.
The adjustable parameters within neurons are weights and biases. As the network learns, these parameters are fine-tuned to determine the input signal strength. This tuning process is akin to the network’s evolving knowledge base. Certain configurations, known as hyperparameters, can be modified before training, influencing factors like learning speed and training duration, akin to optimizing system performance.
During training, the neural network is exposed to data, makes predictions based on existing knowledge (weights and biases), and evaluates prediction accuracy. This evaluation employs a loss function, the network’s “scorekeeper.” After making predictions, the loss function calculates the deviation from actual results. The primary training objective is minimizing errors.
Backpropagation plays a pivotal role in the learning process. Once errors or losses are identified, backpropagation adjusts weights and biases to reduce these errors. It functions as a feedback mechanism, identifying neurons contributing to errors and refining them for improved future predictions.
Techniques such as “gradient descent” efficiently adjust weights and biases. Gradient descent is a methodical approach to reaching the lowest point in incremental steps. Imagine navigating rough terrain, aiming to find the lowest point. The path followed, guided by gradient descent, leads to ever-lower points.
Lastly, a crucial component of neural networks is the activation function. This function decides whether to activate a neuron based on a weighted sum of its inputs and a bias.
Neural Networks in Deep Learning
Neural networks excel at learning and identifying patterns directly from data without predefined rules. These networks comprise several fundamental components:
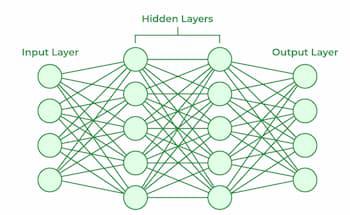
- Neurons: Basic units receiving inputs, each governed by a threshold and an activation function.
- Connections: Information carriers between neurons, regulated by weights and biases.
- Weights and Biases: Parameters determining connection strength and impact.
- Propagation Functions: Mechanisms facilitating data processing and transfer between neuron layers.
- Learning Rule: A method adjusting weights and biases over time for improved accuracy.
Learning in neural networks involves a structured three-stage process:
- Input Computation: Data is fed into the network, serving as learning material.
- Output Generation: Based on available parameters, the network produces outputs.
- Iterative Refinement: Through weight and bias adjustments, the network refines outputs, enhancing task performance.
Neural networks were first proposed in 1944 by Warren McCullough and Walter Pitts (University of Chicago researchers), who later joined MIT in 1952. Initially, neural networks were a significant research area in neuroscience and computer science until 1969. However, the field waned after MIT mathematicians Marvin Minsky and Seymour Papert questioned its viability in 1969. The technique saw a resurgence in the 1980s, waned in the early 2000s, and has recently thrived due to GPU advancements.
The history of neural networks extends further back than many realize. The notion of a “thinking machine” dates to ancient Greece. However, let’s explore some pivotal events in recent history:
- 1943: Warren S. McCulloch and Walter Pitts published “A logical calculus of the ideas immanent in nervous activity,” exploring how interconnected neurons produce complex patterns, comparing them to Boolean logic (0/1 or true/false statements).
- 1958: Frank Rosenblatt developed the perceptron, documented in “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain.” He advanced McCulloch and Pitts’ work using IBM 704 to teach computers to distinguish between differently marked cards.
- 1974: Paul Werbos was the first in the US to note backpropagation’s application in neural networks in his PhD thesis.
- 1989: Yann LeCun’s research demonstrated using constraints in backpropagation and neural network architecture for training algorithms, successfully recognizing postal code digits for the US Postal Service.
Various neural network types are designed for specific tasks and applications:
- Feed Forward Neural Networks: The simplest type, where information moves unidirectionally.
- Recurrent Neural Networks (RNN): Characterized by feedback loops for information persistence, used for time series data and tasks like stock market predictions.
- Convolutional Neural Networks (CNN): Primarily used for image recognition, pattern recognition, and computer vision, leveraging linear algebra principles like matrix multiplication.
- Radial Basis Function Neural Networks: Employed for function approximation problems.
Image recognition was among the first successful neural network applications. However, their utility has expanded rapidly to include:
- Chatbots, computer vision, NLP (Natural Language Processing), translation and language generation, speech recognition, recommendation engines, stock market predictions, delivery driver route planning and optimization, drug discovery and development, social media, personal assistants, pattern recognition, regression analysis, process and quality control, social network filtering, targeted marketing through behavioral data insights, generative AI, quantum chemistry, and data visualization.
Deep learning, a subset of machine learning, teaches computers to perform tasks by learning from examples, akin to human cognitive processes. But how can computers learn? By feeding them extensive datasets. A child learns about the world through senses like sight, hearing, and smell. Similarly, algorithms process varied data, such as visual and audio, to mimic human learning.
Deep learning employs neural networks to simulate human brain functionality, teaching computers to perform classification tasks and recognize patterns in photos, text, audio, and other data types. They automate tasks like image identification or audio transcription, typically requiring human intelligence.
The human brain comprises millions of interconnected neurons collaborating to process information. Deep learning involves neural networks with multiple software node layers working together, trained using large labeled datasets and neural network architectures.
In essence, deep learning enables computers to learn by example. For instance, imagine teaching a toddler what a dog is. By pointing to objects and saying “dog,” the toddler learns to identify dogs through parental feedback. Similarly, a computer learns to recognize a “car” by analyzing numerous images, identifying common patterns independently. This encapsulates deep learning.
In technical terms, deep learning utilizes neural networks, inspired by the human brain, comprising interconnected node layers. More layers render the network “deeper,” enabling it to learn intricate features and execute sophisticated tasks.

While all deep learning models are neural networks, not all neural networks qualify as deep learning. Deep learning refers to neural networks with three or more layers. These networks strive to emulate human brain behavior, facilitating learning from extensive data. Although a single-layer network can approximate predictions, additional hidden layers enhance accuracy.
The introduction of the Neural Processing Unit (NPU) accelerates artificial intelligence tasks. Apple has integrated NPUs in its chips for years, a trend gaining momentum as AI processes and tools become widespread.
What is an NPU?
Essentially, an NPU is a specialized processor executing machine learning algorithms, unlike traditional CPUs and GPUs. NPUs excel at processing large data volumes in parallel, facilitating tasks like image recognition and natural language processing. When integrated with GPUs, NPUs can handle specific tasks such as object detection or image acceleration.
Why do we need an NPU?
AI tools demand dedicated processing power, varying by industry, use case, and software. With productive AI use cases on the rise, a revamped computational architecture tailored for AI is essential. Beyond the CPU and GPU, NPUs are designed specifically for AI tasks. Pairing an NPU with the appropriate processor enables advanced AI experiences, optimizing application performance and efficiency while reducing power consumption and enhancing battery life.