
Discover Meta’s groundbreaking Llama API unveiled at LlamaCon, revolutionizing AI with cutting-edge capabilities for developers.

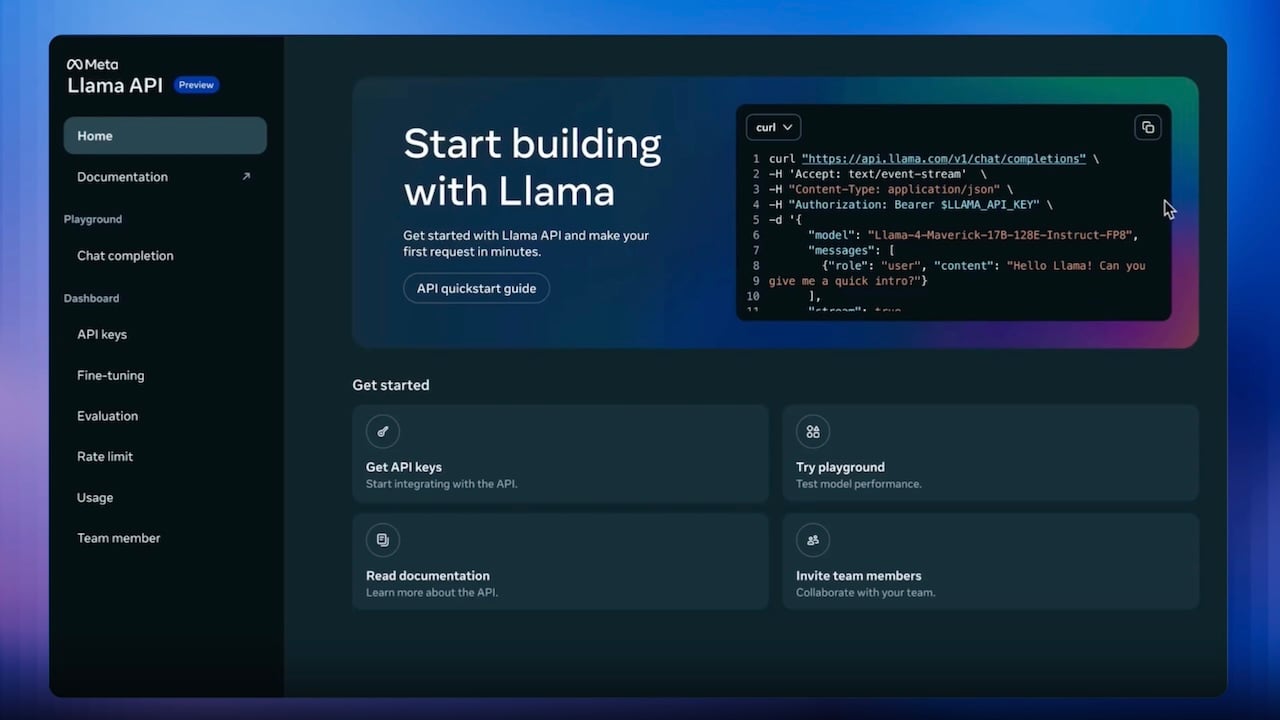

In an exciting development at the inaugural LlamaCon, Meta announced the launch of the Llama API, which is now available as a limited free preview for developers worldwide. This innovative API will empower developers to explore and experiment with different Llama models, featuring the latest Llama 4 Scout and Llama 4 Maverick models.

The Llama API comes with one-click API key generation and offers lightweight SDKs for TypeScript and Python, simplifying the integration process for developers. Additionally, to facilitate the transition of OpenAI-based applications, the Llama API is designed to be compatible with the OpenAI SDK.

Meta has joined forces with technology leaders Cerebras and Groq to deliver unprecedented inference speeds for the Llama API. Cerebras claims that their specialized Llama 4 model, available in the API, can achieve token generation speeds up to 18 times faster than traditional GPU-based solutions from industry giants like NVIDIA.
According to Artificial Analysis, a benchmarking authority, the Cerebras solution achieved a remarkable throughput of over 2,600 tokens per second for Llama 4 Scout, outpacing ChatGPT’s 130 tokens per second and DeepSeek’s 25 tokens per second.

Andrew Feldman, CEO and Co-Founder of Cerebras, expressed, “Cerebras is thrilled to position the Llama API as the world’s fastest inference API. Developers focusing on agent and real-time applications demand speed, and with Cerebras integrated into the Llama API, they can craft AI systems that outperform traditional GPU-based inference clouds.” Developers can leverage this ultra-fast Llama 4 inference by selecting Cerebras as their model option within the Llama API.
While Llama 4 Scout is also available from Groq, it currently operates at a speed of 460 tokens per second. Though this is approximately six times slower than the Cerebras solution, it remains four times faster than conventional GPU-based alternatives.





















Yorum Yap